from numpy import random,argsort,argmax,bincount,int_,array,vstack,round
from pylab import scatter,show
def knn_classifier(x, D, labels, K):
""" Classify the vector x
D - data matrix (each row is a pattern).
labels - class of each pattern.
K - number of neighbour to use.
Returns the class label and the neighbors indexes.
"""
neig_idx = knn_search(x,D,K)
counts = bincount(labels[neig_idx]) # voting
return argmax(counts),neig_idx
Let's test the classifier on some random data:
# generating a random dataset with random labels data = random.rand(2,150) # random points labels = int_(round(random.rand(150)*1)) # random labels 0 or 1 x = random.rand(2,1) # random test point # label assignment using k=5 result,neig_idx = knn_classifier(x,data,labels,5) print 'Label assignment:', result # plotting the data and the input pattern # class 1, red points, class 0 blue points scatter(data[0,:],data[1,:], c=labels,alpha=0.8) scatter(x[0],x[1],marker='o',c='g',s=40) # highlighting the neighbours plot(data[0,neig_idx],data[1,neig_idx],'o', markerfacecolor='None',markersize=15,markeredgewidth=1) show()The script will show the following graph:
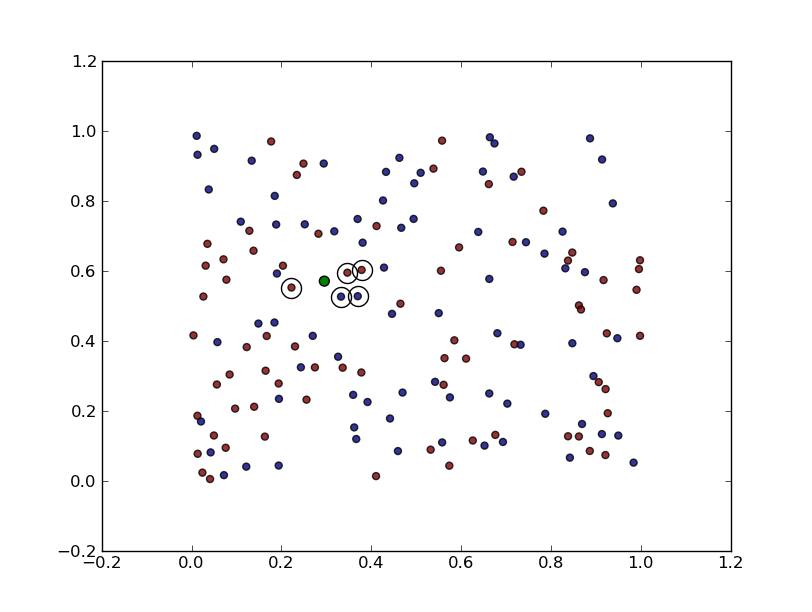
The query vector is represented with a green point and we can see that the 3 out of 5 nearest neighbors are red points (label 1) while the remaining 2 are blue (label 2).
The result of the classification will be printed on the console:
Label assignment: 1As we expected, the green point have been assigned to the class with red markers.


