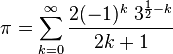The following function is a three-line implementation of the
Principal Component Analysis (PCA). It is inspired by the function
princomp of the matlab's statistics toolbox.
from numpy import mean,cov,double,cumsum,dot,linalg,array,rank
from pylab import plot,subplot,axis,stem,show,figure
def princomp(A):
""" performs principal components analysis
(PCA) on the n-by-p data matrix A
Rows of A correspond to observations, columns to variables.
Returns :
coeff :
is a p-by-p matrix, each column containing coefficients
for one principal component.
score :
the principal component scores; that is, the representation
of A in the principal component space. Rows of SCORE
correspond to observations, columns to components.
latent :
a vector containing the eigenvalues
of the covariance matrix of A.
"""
# computing eigenvalues and eigenvectors of covariance matrix
M = (A-mean(A.T,axis=1)).T # subtract the mean (along columns)
[latent,coeff] = linalg.eig(cov(M)) # attention:not always sorted
score = dot(coeff.T,M) # projection of the data in the new space
return coeff,score,latent
(In this other post you can find an updated version of this function).
In the following test a 2D dataset wil be used. The result of this test is a plot with the two principal components (dashed lines), the original data (blue dots) and the new data (red stars). As we expected the first principal component describes the direction of maximum variance and the second is orthogonal to the first.
A = array([ [2.4,0.7,2.9,2.2,3.0,2.7,1.6,1.1,1.6,0.9],
[2.5,0.5,2.2,1.9,3.1,2.3,2,1,1.5,1.1] ])
coeff, score, latent = princomp(A.T)
figure()
subplot(121)
# every eigenvector describe the direction
# of a principal component.
m = mean(A,axis=1)
plot([0, -coeff[0,0]*2]+m[0], [0, -coeff[0,1]*2]+m[1],'--k')
plot([0, coeff[1,0]*2]+m[0], [0, coeff[1,1]*2]+m[1],'--k')
plot(A[0,:],A[1,:],'ob') # the data
axis('equal')
subplot(122)
# new data
plot(score[0,:],score[1,:],'*g')
axis('equal')
show()
In this second example princomp(.) is tested on a 4D dataset. In this example the matrix of the data is rank deficient and only the first two components are necessary to bring the information of the entry dataset.
A = array([[-1, 1, 2, 2],
[-2, 3, 1, 0],
[ 4, 0, 3,-1]],dtype=double)
coeff, score, latent = princomp(A)
perc = cumsum(latent)/sum(latent)
figure()
# the following plot shows that first two components
# account for 100% of the variance.
stem(range(len(perc)),perc,'--b')
axis([-0.3,4.3,0,1.3])
show()
print 'the principal component scores'
print score.T # only the first two columns are nonzero
print 'The rank of A is'
print rank(A) # indeed, the rank of A is 2
Coefficients for principal components
[[ 1.464140e+00 1.588382e+00 0.000000e+00 -4.440892e-16]
[ 2.768170e+00 -1.292503e+00 -2.775557e-17 6.557254e-16]
[ -4.232310e+00 -2.958795e-01 1.110223e-16 -3.747002e-16]]
The rank of A is
2